
Hi, Sorry for the delay. I made an image using Disk Copy under OS 9. The image seems to contain a desktop database by default. Is there any means of creating images without a DTDB using DiskCopy so that I can compare ?
Thanks!
Regards, Nandini HEngen
Hi!
Make an image exactly equal using the OS X utilities, then compare.
What license will you use in that cross-platform application?
Regards
-----Original Message----- From: hfs-user-admin@lists.mars.org [mailto:hfs-user-admin@lists.mars.org] On Behalf Of nand@gmx.de Sent: Friday, January 24, 2003 9:05 AM To: hfs-user@lists.mars.org Subject: [hfs-user] Mac OS-X and HFS
Hello Listers, I had worked on a cross-platform application a little while ago to create images based on the HFS-format. My images work fine when recorded on to a CD and read under Mac OS 9 but someone who tried reading them under Jaguar complained that not all files got displayed. He had tried creating a very simple image with three files at the root level named bild.bmp, screenshot.jpg and test1.mpg. The problem that only one file (bild.bmp) is displayed initially as present. After searching for "." in the window all three files are shown in the window.
Now what could this be due to ? I really want to get to the root of the problem. Considering that the image is perfectly readable under OS 9 I *have to* come to the conclusion that the OS-X Finder is making some specific assumptions which deviate from the filesystem format specifications released by Apple.
Any suggestions/ comments as to what this could be due to and why I don't have a problem under OS 9 as well ? Do you think it could have something to do with the filenames or the filetypes ? Images with a large number of text-files and pdf's seem to be getting displayed under OS-X perfectly.
Best Regards, Nandini
-- +++ GMX - Mail, Messaging & more http://www.gmx.net +++ NEU: Mit GMX ins Internet. Rund um die Uhr für 1 ct/ Min. surfen!

Hi everybody,
A little question:
In the device/driver descriptor block (sector 0 of a disk), the first three fields are: sbSig: Integer; {device signature} sbBlkSize: Integer; {block size of the device} sbBlkCount: LongInt; {number of blocks on the device}
For sbBlkSize, I always got 512 on magnetic hard disks and CD-ROMs (magneto-optical disks are another matter). Now, what happens when the disk contains more than 0xFFFFFFFF * 0x0200 bytes? This could be the case with a DVD-ROM, for instance.

There is a limit on the maximum size of any particular disk of 4 billion (2^32) * the block size, or 0xFFFFFFFF * sbBlkSize. If sbBlkSize is 0x0200 as you say then the limit is about 2 Gb. I'd guess that to get around this either DVD's use a larger block size (0x2000 would adequately cover the 4.5Gb physical maximum on a DVD) or use HFS+ or some other system. Remember the only real reason why it is bad to use large block sizes is the wasteage that occurs with small files. On a DVD you typically have less than 20 files, some of which are huge so the lost space is minimal.
Pierre Duhem wrote:
Hi everybody,
A little question:
In the device/driver descriptor block (sector 0 of a disk), the first three fields are: sbSig: Integer; {device signature} sbBlkSize: Integer; {block size of the device} sbBlkCount: LongInt; {number of blocks on the device}
For sbBlkSize, I always got 512 on magnetic hard disks and CD-ROMs (magneto-optical disks are another matter). Now, what happens when the disk contains more than 0xFFFFFFFF * 0x0200 bytes? This could be the case with a DVD-ROM, for instance.
Hi Simon,
SB> There is a limit on the maximum size of any particular disk of 4 billion SB> (2^32) * the block size, or 0xFFFFFFFF * sbBlkSize. If sbBlkSize is SB> 0x0200 as you say then the limit is about 2 Gb. SB> I'd guess that to get around this either DVD's use a larger block size SB> (0x2000 would adequately cover the 4.5Gb physical maximum on a DVD) or SB> use HFS+ or some other system.
As far as I know, HFS+ volumes also have the same Device Descriptor Block in sector 0. More, one could easily have a device with a first partition in HFS and a second in HFS+. This block size is only used in this DDB and in the partition table (the fourth unsigned long).
Therefore, it would not be that difficult to switch to another block size just to manage the DDB and the partition table. One would in that case put the beginning of the partition table, not in sector 1, but in block 1 (that is, sector = block size / 512).
SB> Remember the only real reason why it is bad to use large block sizes is SB> the wasteage that occurs with small files. On a DVD you typically have SB> less than 20 files, some of which are huge so the lost space is minimal.
This block size doesn't have anything to do with the allocation block/cluster size, that is with the size of the chunks used to manage the data space in the allocation bitmaps. As a matter of fact, HFS+ volumes frequently use 0x1000-byte blocks, but switch to 0x2000 for bigger disks (from 100GB, I think).
On the other hand, DVD are not only used to store movies and likewise big files, but also to store plain data files, when the size of a CD-ROM is not enough. For such volumes, keeping the allocation block size to 0x800 bytes is an advantage, in particular if you build hybrid data structures with an ISO/Joliet catalog pointing to the same data pool.
Hi,
Following my messages, and after checking the DDB of a 250GB drive formatted under Max OS X.2, I redid my homework:
0xFFFFFFFF * 0x200 = 0x1FFFFFFFE00, that is 2,199,023,255,040, that is 2,199GB.
I don't think such biests are for tomorrow morning.
In fact, I asked this question because I saw in one of my DVD images a FF in the MSB byte of the block number long and was afraid of overflowing rather soon.
It was in fact the overflow of the max capacity of a signed long in my code. Remains to find where...
Thanks anyway.
Hello everybody,
I'm using Norton Disk Doctor v. 8 to check the HFS/HFS+ volumes I'm producing and get a curious error message.
Norton says that the alphabetical order of the items in a node is incorrect. It proposes to fix the matter and does it apprently. When I check in the catalog node, however, I find it put a hidden folder named '0000HFS+ Private Data' (with four null at the beginning of the Unicode string) at the end of the current folder.
I thought that alphabetical order problems were a matter of the past (remember the funny order of the accented letters?).
Does it make sense for you to put an Unicode character of 0x0000 at the very end of the list?

On Apr 19, 2004, at 5:58 AM, Pierre Duhem wrote:
Norton says that the alphabetical order of the items in a node is incorrect. It proposes to fix the matter and does it apprently. When I check in the catalog node, however, I find it put a hidden folder named '0000HFS+ Private Data' (with four null at the beginning of the Unicode string) at the end of the current folder.
I thought that alphabetical order problems were a matter of the past (remember the funny order of the accented letters?).
Does it make sense for you to put an Unicode character of 0x0000 at the very end of the list?
Yes, it does make sense. It's part of the way HFS Plus handles case-insensitive comparisons with Unicode. See the Case-Insensitive String Comparison Algorithm section of Tech Note 1150: HFS Plus Volume Format: <http://developer.apple.com/technotes/tn/ tn1150.html#StringComparisonAlgorithm>
The reason has to do with certain "ignorable" Unicode characters. Some Unicode code points act as hints, and do not affect the comparison (a string with these ignorable characters is considered identical to a string without ignorables). The easy way to handle them in the code was to map them to 0 during the comparison. But since null (0) is a valid character in an HFS Plus name, it gets mapped to 0xFFFF (which is not valid Unicode) during the comparison. That's why nulls sort last on HFS Plus.
-Mark
Mark,
MD> On Apr 19, 2004, at 5:58 AM, Pierre Duhem wrote:
Norton says that the alphabetical order of the items in a node is incorrect. It proposes to fix the matter and does it apprently. When I check in the catalog node, however, I find it put a hidden folder named '0000HFS+ Private Data' (with four null at the beginning of the Unicode string) at the end of the current folder.
I thought that alphabetical order problems were a matter of the past (remember the funny order of the accented letters?).
Does it make sense for you to put an Unicode character of 0x0000 at the very end of the list?
MD> Yes, it does make sense. It's part of the way HFS Plus handles MD> case-insensitive comparisons with Unicode. See the Case-Insensitive MD> String Comparison Algorithm section of Tech Note 1150: HFS Plus Volume MD> Format: MD> <http://developer.apple.com/technotes/tn/ MD> tn1150.html#StringComparisonAlgorithm>
MD> The reason has to do with certain "ignorable" Unicode characters. Some MD> Unicode code points act as hints, and do not affect the comparison (a MD> string with these ignorable characters is considered identical to a MD> string without ignorables). The easy way to handle them in the code MD> was to map them to 0 during the comparison. But since null (0) is a MD> valid character in an HFS Plus name, it gets mapped to 0xFFFF (which is MD> not valid Unicode) during the comparison. That's why nulls sort last MD> on HFS Plus.
Thanks a lot. I had read this document in the past, and this very piece, but had not noticed this special treatment for the null character. I'll correct my code in this sense.
Thanks again.
Hi everybody,
Is there a recommendation by Apple concerning the size of the Catalog File (and of the Extents Overflow File), depending on the size of the physical drive?
For instance, I get following values when formatting with the Disk Utility under Mac OS X.2: Vol Ext*Node Size Cat*Node size 100MB 191*4096 191*4096 40GB 1586*4096 4864*8192 250GB 2048*4096 8704*8192
Which threshold would be reasonnable to switch to 8192-byte nodes?
Is it reasonnable to think that, for the time being, 8192 is the biggest node size to be used?
On Apr 23, 2004, at 6:36 AM, Pierre Duhem wrote:
Is there a recommendation by Apple concerning the size of the Catalog File (and of the Extents Overflow File), depending on the size of the physical drive?
There is no official recommendation, but I'll describe the default behavior in Mac OS X version 10.3. If you're curious, you can download the sources for newfs_hfs from Mac OS X 10.3; it is part of the diskdev_cmds project in Darwin. The URL is: <http://www.opensource.apple.com/darwinsource/tarballs/apsl/ diskdev_cmds-277.1.tar.gz>
For volumes less than 1GB, the default catalog node size is 4KB; for larger volumes, the default is 8KB. The default extents node size is 4KB.
The default sizes of the catalog and extents files vary with the size of the volume. For volumes less than 1GB, the default size for both B-trees is 1/128 of the size of the volume, but at least 8 nodes. For larger volumes, the following table gives the default sizes:
short clumptbl[CLUMP_ENTRIES * 2] = { /* * Volume Catalog Extents * Size Clump (MB) Clump (MB) */ /* 1GB */ 4, 4, /* 2GB */ 6, 4, /* 4GB */ 8, 4, /* 8GB */ 11, 5, /* 16GB */ 14, 5, /* 32GB */ 19, 6, /* 64GB */ 25, 7, /* 128GB */ 34, 8, /* 256GB */ 45, 9, /* 512GB */ 60, 11, /* 1TB */ 80, 14, /* 2TB */ 107, 16, /* 4TB */ 144, 20, /* 8TB */ 192, 25, /* 16TB */ 256, 32 };
The "clump size" here is both the initial size of the B-tree (in megabytes), and is the default amount to grow the tree by when it gets full. These numbers are not special; they are educated guesses based on general usage.
When initializing a volume, I suggest that the bitmap (allocation file) and extents B-tree come before (lower disk addresses) than the catalog B-tree. Also, set up the nextAllocation field of the volume header to be well past the end of the catalog (perhaps 2-4 times the size of the catalog beyond the end of the catalog). This gives the catalog lots of room to grow contiguously as you initially populate the volume, but lets you eventually use the space for data if the catalog doesn't need to grow that much.
Which threshold would be reasonnable to switch to 8192-byte nodes?
Apple's default is 1GB or larger volumes. We noticed a non-trivial performance gain when using 8KB nodes compared to 4KB nodes, due to the large number of pathname lookups in Mac OS X. The performance difference was negligible for Mac OS 8 and 9 (where applications use the parent directory ID and leaf name much more often than full path names).
Is it reasonnable to think that, for the time being, 8192 is the biggest node size to be used?
It's the largest default node size created by any Apple OS. But it is possible for nodes to be as large as 32KB.
The HFS Plus volume format is described here: http://developer.apple.com/technotes/tn/tn1150.html
That technical note was updated at the beginning of March, 2004. A lot of information related to Mac OS X (including the journal, metadata zone, and a case-sensitive variant) was added in that update.
-Mark
Mark,
Thanks a _lot_ for your answer. I'll have a look at the code you gave me a pointer to.
Hello,
I didn't like very much the code I had to check for an overflow of the binary table used in the Extents and Catalog B-trees for the node allocation.
Therefore, I had the idea to build this list when formatting. I followed the specs and built a simply linked list from the tree header. All nodes are empty, with only the downward pointer, the 2 as node kind, a 1 since there is a single entry and the two offsets at the end, 00 0E for the binary table and 01 FC (in the case of a HFS node) pointing to itself.
But Mac OS X doesn't seem to like my idea, refuses to mount even an empty volume, as soon as there is a map node linked list.
Who should build this list? Is it against the rule to build an empty node list?

On Apr 29, 2004, at 7:25 AM, Pierre Duhem wrote:
Hello,
I didn't like very much the code I had to check for an overflow of the binary table used in the Extents and Catalog B-trees for the node allocation.
Therefore, I had the idea to build this list when formatting
Of course, even THAT could eventually still overflow...
I followed the specs and built a simply linked list from the tree header. All nodes are empty, with only the downward pointer,
What do you mean by this? IIRC correctly, the map nodes are linked back and forth via the usual forward/backward link fields in the node header? Of course, for the definitive word look to Mark's recently updated tech note!
the 2 as node kind, a 1 since there is a single entry and the two offsets at the end, 00 0E for the binary table and 01 FC (in the case of a HFS node) pointing to itself.
But Mac OS X doesn't seem to like my idea, refuses to mount even an empty volume, as soon as there is a map node linked list.
Have you tried running fsck_hfs from a command-line shell with the "-d" option (along with -f if necessary - see 'man fsck_hfs') to see what it generates?
Who should build this list? Is it against the rule to build an empty node list?
It's unusual but I believe this would be no different than how a volume would look if the B*-Tree had been grown a lot and then the nodes freed up, right? It'd still have a map node linked to the header but the bitmap field would be empty, so I'd think it SHOULD be OK. I bet there's some other field tripping you up.
Hope that helps, -Pat Dirks.
-- Best Regards Pierre Duhem Logiciels & Services Duhem, Paris (France) duhem@macdisk.com
Patrick,
PD> On Apr 29, 2004, at 7:25 AM, Pierre Duhem wrote:
Hello,
I didn't like very much the code I had to check for an overflow of the binary table used in the Extents and Catalog B-trees for the node allocation.
Therefore, I had the idea to build this list when formatting
PD> Of course, even THAT could eventually still overflow...
Of course, But it is definitively easier to build this linked list from scratch, when your tree is still empty.
I followed the specs and built a simply linked list from the tree header. All nodes are empty, with only the downward pointer,
PD> What do you mean by this? IIRC correctly, the map nodes are linked PD> back and forth via the usual forward/backward link fields in the node PD> header? Of course, for the definitive word look to Mark's recently PD> updated tech note!
The map nodes list is not doubly linked, and has only forward (downward) links. The last node has 00 00 00 00 in the first four bytes, which could be interpreted as a link back to the node 0 (tree header), btw.
the 2 as node kind, a 1 since there is a single entry and the two offsets at the end, 00 0E for the binary table and 01 FC (in the case of a HFS node) pointing to itself.
But Mac OS X doesn't seem to like my idea, refuses to mount even an empty volume, as soon as there is a map node linked list.
PD> Have you tried running fsck_hfs from a command-line shell with the "-d" PD> option (along with -f if necessary - see 'man fsck_hfs') to see what it PD> generates?
My code runs on a PC, under Windows ;-)).
Who should build this list? Is it against the rule to build an empty node list?
PD> It's unusual but I believe this would be no different than how a volume PD> would look if the B*-Tree had been grown a lot and then the nodes freed PD> up, right? It'd still have a map node linked to the header but the PD> bitmap field would be empty, so I'd think it SHOULD be OK. I bet PD> there's some other field tripping you up.
Surely. I'll check again.
On Apr 29, 2004, at 11:40 PM, Pierre Duhem wrote:
Patrick,
PD> On Apr 29, 2004, at 7:25 AM, Pierre Duhem wrote:
Hello,
I didn't like very much the code I had to check for an overflow of the binary table used in the Extents and Catalog B-trees for the node allocation.
Therefore, I had the idea to build this list when formatting
PD> Of course, even THAT could eventually still overflow...
Of course, But it is definitively easier to build this linked list from scratch, when your tree is still empty.
I don't really see why. Why don't you have a look at the hfs code? When the bitmap's full and the B*-Tree is extended it just allocates a new node, updates the header to point to it, and initializes it with a map data structure. No problem, and completely confined to the B*-Tree expansion code. The "allocate-a-node" logic doesn't directly need to be involved.
I followed the specs and built a simply linked list from the tree header. All nodes are empty, with only the downward pointer,
PD> What do you mean by this? IIRC correctly, the map nodes are linked PD> back and forth via the usual forward/backward link fields in the node PD> header? Of course, for the definitive word look to Mark's recently PD> updated tech note!
The map nodes list is not doubly linked, and has only forward (downward) links. The last node has 00 00 00 00 in the first four bytes, which could be interpreted as a link back to the node 0 (tree header), btw.
the 2 as node kind, a 1 since there is a single entry and the two offsets at the end, 00 0E for the binary table and 01 FC (in the case of a HFS node) pointing to itself.
But Mac OS X doesn't seem to like my idea, refuses to mount even an empty volume, as soon as there is a map node linked list.
PD> Have you tried running fsck_hfs from a command-line shell with the "-d" PD> option (along with -f if necessary - see 'man fsck_hfs') to see what it PD> generates?
My code runs on a PC, under Windows ;-)).
Nevertheless, examining your disks on a Mac would be a good debugging tool! If you can't use an external drive like a FireWire drive to practice on, create a disk image of whatever size you like (I believe .dmg files are just block-for-block copies of the device - nothing special) and transfer that to a Mac somehow.
Who should build this list? Is it against the rule to build an empty node list?
PD> It's unusual but I believe this would be no different than how a volume PD> would look if the B*-Tree had been grown a lot and then the nodes freed PD> up, right? It'd still have a map node linked to the header but the PD> bitmap field would be empty, so I'd think it SHOULD be OK. I bet PD> there's some other field tripping you up.
Surely. I'll check again.
-- Best Regards Pierre Duhem Logiciels & Services Duhem, Paris (France) duhem@macdisk.com
Patrick,
PD> On Apr 29, 2004, at 11:40 PM, Pierre Duhem wrote:
Patrick,
PD> On Apr 29, 2004, at 7:25 AM, Pierre Duhem wrote:
Hello,
I didn't like very much the code I had to check for an overflow of the binary table used in the Extents and Catalog B-trees for the node allocation.
Therefore, I had the idea to build this list when formatting
PD> Of course, even THAT could eventually still overflow...
Of course, But it is definitively easier to build this linked list from scratch, when your tree is still empty.
PD> I don't really see why. Why don't you have a look at the hfs code? PD> When the bitmap's full and the B*-Tree is extended it just allocates a PD> new node, updates the header to point to it, and initializes it with a PD> map data structure. No problem, and completely confined to the B*-Tree PD> expansion code. The "allocate-a-node" logic doesn't directly need to PD> be involved.
If it happens that you have to create a map node at a moment where you don't have any free room in the binary table of the tree header (for instance), you are in a catch-22. You need the map node to allocate the node and you need a node to register the newly allocated node.
I followed the specs and built a simply linked list from the tree header. All nodes are empty, with only the downward pointer,
PD> What do you mean by this? IIRC correctly, the map nodes are linked PD> back and forth via the usual forward/backward link fields in the node PD> header? Of course, for the definitive word look to Mark's recently PD> updated tech note!
The map nodes list is not doubly linked, and has only forward (downward) links. The last node has 00 00 00 00 in the first four bytes, which could be interpreted as a link back to the node 0 (tree header), btw.
the 2 as node kind, a 1 since there is a single entry and the two offsets at the end, 00 0E for the binary table and 01 FC (in the case of a HFS node) pointing to itself.
But Mac OS X doesn't seem to like my idea, refuses to mount even an empty volume, as soon as there is a map node linked list.
PD> Have you tried running fsck_hfs from a command-line shell with the "-d" PD> option (along with -f if necessary - see 'man fsck_hfs') to see what it PD> generates?
My code runs on a PC, under Windows ;-)).
PD> Nevertheless, examining your disks on a Mac would be a good debugging PD> tool! If you can't use an external drive like a FireWire drive to PD> practice on, create a disk image of whatever size you like (I believe PD> .dmg files are just block-for-block copies of the device - nothing PD> special) and transfer that to a Mac somehow.
Of course. I have a Mac running Mac OS X.2 to do my checks. And I use Norton v. 8 to do the checks, as well as the Disk Utility. As a matter of fact, I use a Zip 100 for little volumes and two FireWire Maxtor of 40 and 250GB for bigger tests.
The point is that you can't manage to have to up to date programming computers with all necessary tools correctly set. If I had some Unix culture, this would definitively be easier, but I don't ;-)).
Thanks for writing.
Hello,
While reading the latest version of TN1150, I stumbled on the HFSX specification. I understand that this version of HFS+ should bring some simplifications for managing files coming from Unix volumes, while keeping case-sensitive filenames.
Is this format already supported by Mac OS X.3 disk utilities?
On May 6, 2004, at 3:15 AM, Pierre Duhem wrote:
While reading the latest version of TN1150, I stumbled on the HFSX specification. I understand that this version of HFS+ should bring some simplifications for managing files coming from Unix volumes, while keeping case-sensitive filenames.
Is this format already supported by Mac OS X.3 disk utilities?
It is supported by the command line utilities in Mac OS X 10.3.x. The Disk Utility application lets you select HFSX as a volume format when erasing on Mac OS X Server only.
Note that HFSX volumes can be either case sensitive or case insensitive (though if you want case insensitive, you might as well choose HFS Plus for greater compatibility). TN1150 describes how to tell whether filenames are case sensitive.
-Mark
Mark,
Seen in a report by fsck_hfs:
**Checking Catalog hierarchy. Invalid directory item count (It should be 8 instead of 393216)
My code had indeed forgotten to register two files, but the message forgets to swap the value (393216 == 6 in bigendian, or the other way around).
Hello,
Norton v. 8, when checking some of my volumes, complains about dates. For instance : The files have creation dates that are inconsistent or outside the expected range.
Dates are computed that way: - use of unix (C lib) time/filetime functions to get the number of seconds from January the 1st, 1970, - add the number of seconds from January 1st, 1904 - add the timezone + summertime (-7200 seconds currently for Paris/Madrid) to get the UTC/GMT time.
Following the HFS+ spec, I don't add the timezone + summertime for the volume dates.
That way, I have correct dates. PC files copied to a Macintosh volume appear with a correct date on a Mac, and so on.
I don't understand what Norton's error message could mean.
Any clue?

On May 7, 2004, at 4:43 AM, Pierre Duhem wrote:
Norton v. 8, when checking some of my volumes, complains about dates. For instance : The files have creation dates that are inconsistent or outside the expected range.
Dates are computed that way:
- use of unix (C lib) time/filetime functions to get the number of
seconds from January the 1st, 1970,
- add the number of seconds from January 1st, 1904
- add the timezone + summertime (-7200 seconds currently for
Paris/Madrid) to get the UTC/GMT time.
Following the HFS+ spec, I don't add the timezone + summertime for the volume dates.
That way, I have correct dates. PC files copied to a Macintosh volume appear with a correct date on a Mac, and so on.
I don't understand what Norton's error message could mean.
Any clue?
Keep in mind that UNIX dates (seconds since Jan. 1, 1970) are signed while HFS dates (seconds since Jan. 1, 1904) are unsigned.
UNIX HFS Date (UTC) ========== ========== ==================== 0x80000000 ---------- Dec 13 20:45:52 1901 0x83da4f80 0x00000000 Jan 1 00:00:00 1904 0x00000000 0x7c25b080 Jan 1 00:00:00 1970 0x7fffffff 0xfc25b07f Jan 19 03:14:07 2038 ---------- 0xffffffff Feb 6 06:28:15 2040
HTH.

Hello,
Still struggling with some B-tree managing code.
On some medium (HFS, 60 MB, USB key), I get following error :
Invalid index link (4, 389)
389 is the root (4th level) of this medium containing about 2000 very small files (1024 bytes, just for the fun of testing).
The weird thing about this is that the link of the 4th entry of this root node seems correct, to the 3rd level of the tree. I even checked whether counting begins at 0 or 1...
fsck_hfs tells that it can't correct the error because the volume is mounted with writing. I unmount the volume, run the utility again and get a clean result.
Now, checking the dump I did before and the one I did after that, I only have some little changes (date/time of the volume, data/time of .DS_Store, contents of DS_Store, probably to reflect the folder I created), but noting in the node 389 or even in the rest of the catalog (beside the date/time of .DS_Store).
Any clue?
Hi,
No, it's not complaining about the 4th entry in node 389; it's saying the node link field of node 389 of file id 4 (the catalog B*-tree), i.e. the root is bad. Presumably the links (forward and backwards) should be 0, unless you have an expanded root bitmap, in which case a separate map node would've been added and linked in?
-Patrick.
On Sep 16, 2004, at 9:38 AM, Pierre Duhem wrote:
Hello,
Still struggling with some B-tree managing code.
On some medium (HFS, 60 MB, USB key), I get following error :
Invalid index link (4, 389)
389 is the root (4th level) of this medium containing about 2000 very small files (1024 bytes, just for the fun of testing).
The weird thing about this is that the link of the 4th entry of this root node seems correct, to the 3rd level of the tree. I even checked whether counting begins at 0 or 1...
fsck_hfs tells that it can't correct the error because the volume is mounted with writing. I unmount the volume, run the utility again and get a clean result.
Now, checking the dump I did before and the one I did after that, I only have some little changes (date/time of the volume, data/time of .DS_Store, contents of DS_Store, probably to reflect the folder I created), but noting in the node 389 or even in the rest of the catalog (beside the date/time of .DS_Store).
Any clue?
-- Bien à vous Pierre Duhem mailto:pierre@duhem.com
Patrick,
PD> No, it's not complaining about the 4th entry in node 389; it's saying PD> the node link field of node 389 of file id 4 (the catalog B*-tree), PD> i.e. the root is bad. Presumably the links (forward and backwards) PD> should be 0, unless you have an expanded root bitmap, in which case a PD> separate map node would've been added and linked in?
Thanks for the correction.
I'll check.
Patrick,
PD> No, it's not complaining about the 4th entry in node 389; it's saying PD> the node link field of node 389 of file id 4 (the catalog B*-tree), PD> i.e. the root is bad. Presumably the links (forward and backwards) PD> should be 0, unless you have an expanded root bitmap, in which case a PD> separate map node would've been added and linked in?
I had the time to redo my tests and I'm not wiser.
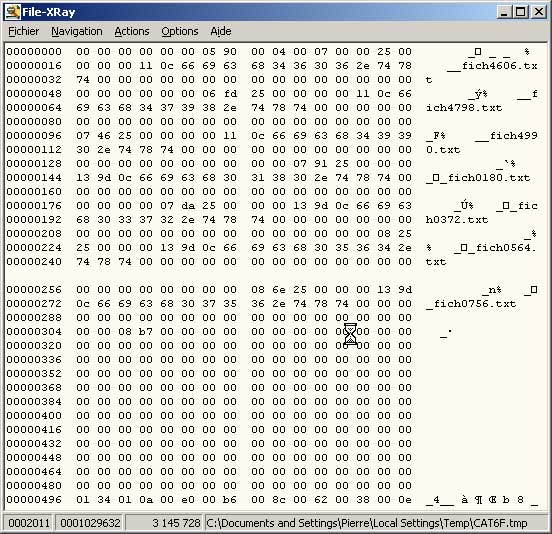
I get the error : Invalid index link 4, 2011
This should mean that the catalog (4) is somehow corrupted in node 2011. I'm attaching a dump of this node. This is a node at level 4 (the root is one level higher, at level 5). This is the last of 4 nodes, which seem to be correctly linked.
If I copy all 6000 files to the Macintosh hard disk, the copy works fine and the content of the files is also correct (files are named according to their content to simplify the job, that is file0000.txt contains 1024 * '0000', etc.).
Thank you for your comments.
{kind=link}
It's hard to say from this dump alone. This node should have no subsequent nodes at its level and its immediate predecessor should be node 0x0590. You should look in the root node to see that (a) this is, in fact, the rightmost record below the root and that (b) the node just before it is 0x0590. You should also check node 0x0590 and make sure its forward link (after converting to decimal) is this node, 2011.
Hope that helps, -Patrick.
On Sep 22, 2004, at 6:47 AM, Pierre Duhem wrote:
Patrick,
PD> No, it's not complaining about the 4th entry in node 389; it's saying PD> the node link field of node 389 of file id 4 (the catalog B*-tree), PD> i.e. the root is bad. Presumably the links (forward and backwards) PD> should be 0, unless you have an expanded root bitmap, in which case a PD> separate map node would've been added and linked in?
I had the time to redo my tests and I'm not wiser.
I get the error : Invalid index link 4, 2011
This should mean that the catalog (4) is somehow corrupted in node 2011. I'm attaching a dump of this node. This is a node at level 4 (the root is one level higher, at level 5). This is the last of 4 nodes, which seem to be correctly linked.
If I copy all 6000 files to the Macintosh hard disk, the copy works fine and the content of the files is also correct (files are named according to their content to simplify the job, that is file0000.txt contains 1024 * '0000', etc.).
Thank you for your comments.
-- Best Regards Pierre Duhem Logiciels & Services Duhem, Paris (France) duhem@macdisk.com <2011.jpg>
Hello,
Still plagued with this "bad map node linkage" (E_MapLk in SVerify2.c)
The BTMapChk pseudocode is:
Calculate mapsize ((totalNodes + 7) / 8) Walk the map node forward links Do some formal checks Calculate the size of the map in the current node Substract this size from mapsize If no more forward links, break If mapsize is not null (the node number being not null is not a problem in my case), rise the E_MapLk error.
That means that it is an error to have several correctly linked map nodes to manage the beginning of the catalog, but not enough (yet) to manage the whole catalog.
On the other hand, it is not an error to build an empty catalog with no map nodes.
That means also that, when you build the first map node outside of the B-Tree header, you have to allocate and link all the nodes.
Am I on the spot, or totally wrong?
Thanks for your comments.
On Oct 5, 2004, at 7:55 AM, Pierre Duhem wrote:
Hello,
Still plagued with this "bad map node linkage" (E_MapLk in SVerify2.c)
The BTMapChk pseudocode is:
Calculate mapsize ((totalNodes + 7) / 8) Walk the map node forward links Do some formal checks Calculate the size of the map in the current node Substract this size from mapsize If no more forward links, break If mapsize is not null (the node number being not null is not a problem in my case), rise the E_MapLk error.
I believe the idea is that there should, at all times, exist exactly enough map nodes to cover the total size of the catalog (or whatever B*-Tree is involved, actually) and that they [ the map nodes ] must all be properly linked in both directions starting from the header node. So...
That means that it is an error to have several correctly linked map nodes to manage the beginning of the catalog, but not enough (yet) to manage the whole catalog.
Yes. Just because nodes are not currently allocated doesn't mean there shouldn't be map nodes to describe that state. For every node in the B*-Tree there must be a bit in a bitmap in a header or map node somewhere to track its allocated/free state.
On the other hand, it is not an error to build an empty catalog with no map nodes.
I'm not sure what that means; if the catalog is large enough (LOGICAL end-of-file, not merely space reserved on disk) then there must be enough map nodes. If the catalog is small, it's perfectly possible that the smaller bitmap in the B*-Tree header node will be sufficient to cover all blocks.
That means also that, when you build the first map node outside of the B-Tree header, you have to allocate and link all the nodes.
All the MAP nodes, yes. When you expand the bitmap with a separate header node it must be linked to and from the previous map node, which may be the B*-Tree header node.
Am I on the spot, or totally wrong?
Sounds like you're at least on the right track.
Hope that helps, -Patrick.
Thanks for your comments.
-- Pierre Duhem duhem@macdisk.com
Patrick,
Am I on the spot, or totally wrong?
PD> Sounds like you're at least on the right track. PD> Hope that helps, PD> -Patrick.
Thanks a lot for your answer. I think one reason why I was confused is because the bitmap of the header node, even in HFS, contains enough room for 256*8 nodes, that is 2048, which happens to be the biggest clump (global or constant in SVerify1.c, I think).
On the other hand, my code produces HFS/HFS+ CD-ROM images, and I allocate a single catalog extent, for which I should build the map linkage immediatly if needed (if the catalog is more than 2048 nodes in HFS).
Well, I know what I'll have to do.
Hello,
While the Allocation File is just another file and can be non continguous (TN 1150), do you think it is conceivable to have it overflow in the Extents Overflow File, i.e. that this file would not be fully allocated amongst the first 8 extents?
On Apr 29, 2004, at 7:25 AM, Pierre Duhem wrote:
I didn't like very much the code I had to check for an overflow of the binary table used in the Extents and Catalog B-trees for the node allocation.
Therefore, I had the idea to build this list when formatting. I followed the specs and built a simply linked list from the tree header. All nodes are empty, with only the downward pointer, the 2 as node kind, a 1 since there is a single entry and the two offsets at the end, 00 0E for the binary table and 01 FC (in the case of a HFS node) pointing to itself.
But Mac OS X doesn't seem to like my idea, refuses to mount even an empty volume, as soon as there is a map node linked list.
Who should build this list? Is it against the rule to build an empty node list?
The B-trees keep track of which nodes are used and which are free by using one or more map records. These map records are just a bitmap, much like the one that is used to keep track of used/free allocation blocks. The first map record is in the B-tree header node (node #0). If the B-tree contains more nodes than there are bits in the header node's map record, then there will be additional map nodes which each contain a single map record. The header node and map nodes form a singly linked list, using the forward link field (the first four bytes of the node). If your B-tree is large enough (has enough nodes), then you definitely do need to create the linked list of map nodes at format time. Similarly, you may have to add map nodes to the end of the linked list if you grow the B-tree (if it now has more nodes than the existing map nodes can track).
It should be OK to create more map nodes than your B-tree strictly needs. I don't think Mac OS X will complain, but third party repair utilities might. Note that Mac OS X will only grow, never shrink, a B-tree.
Some things to verify: * The linked list uses the forward link field in the node header. This is the first four bytes of the node. It should contain the node number of the next node in the linked list, stored in big endian (network) byte order. The forward link of the last node in the linked list should be zero. * The backward link (bytes 4-7 of the node) should be zero. * The node type (byte 8) is 1 for the header node, or 2 for the map nodes. * The node height (byte 9) should be zero for both the header node and map nodes. * The number of records (bytes 10-11) of the map nodes should be set to 1 (again, in big endian, so 00 01). * Bytes 12-13 of the nodes should be zeroes. * The offsets at the end of the node are in the opposite order of the keys in the node. For example, the offsets for HFS (node size = 512) would be the bytes 01 FC 00 0E. The offset (0x000E) for the first record is at the end of the node; the offset for the next record (0x01FC, free space) comes just before that; and so on. * On HFS Plus, the size of a map record must be a multiple of 4 bytes. Since the node header is 14 bytes (not a multiple of 4), and there are two record offsets (4 bytes), there will be two free bytes between the map record and record offsets in a map node. That is, the second offset (the offset to free space) will be the node size minus 6 (bytes xx FA). * Don't forget to mark the header node and any map nodes as in use in the map record(s).
If that doesn't help you figure out the problem, let me know.
By the way, if you want to experiment with how Mac OS X formats volumes, try using disk images. You can use sparse disk images to create volumes much larger than you have physical space for. For example, here's how I created a sparse image of an 80GB HFS Plus volume, with an extents B-tree containing 10,000 nodes, with a node size of 1024:
% hdiutil create -size 80g -type SPARSE -layout NONE myhfs Initializing... Creating... Finishing... created: /Users/mark/myhfs.sparseimage % hdiutil attach -nomount myhfs.sparseimage Initializing... Attaching... Finishing... Finishing... /dev/disk2 % newfs_hfs -n e=1024 -c e=10000 /dev/disk2 Initialized /dev/rdisk2 as a 80 GB HFS Plus volume
Here's a hex dump showing that volume's extents B-tree:
Here's the header node: 00281000 00 00 00 01 00 00 00 00 01 00 00 03 00 00 00 00 |................| 00281010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00281020 04 00 00 0a 00 00 9c 40 00 00 9c 3a 00 00 02 71 |.......@...:...q| 00281030 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 00 |................| 00281040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 002810f0 00 00 00 00 00 00 00 00 fc 00 00 00 00 00 00 00 |................| 00281100 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 002813f0 00 00 00 00 00 00 00 00 03 f8 00 f8 00 78 00 0e |.............x..| The first map node: 00281400 00 00 00 02 00 00 00 00 02 00 00 01 00 00 00 00 |................| 00281410 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 002817f0 00 00 00 00 00 00 00 00 00 00 00 00 03 fa 00 0e |................| Next map node... 00281800 00 00 00 03 00 00 00 00 02 00 00 01 00 00 00 00 |................| 00281810 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00281bf0 00 00 00 00 00 00 00 00 00 00 00 00 03 fa 00 0e |................| 00281c00 00 00 00 04 00 00 00 00 02 00 00 01 00 00 00 00 |................| 00281c10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00281ff0 00 00 00 00 00 00 00 00 00 00 00 00 03 fa 00 0e |................| 00282000 00 00 00 05 00 00 00 00 02 00 00 01 00 00 00 00 |................| 00282010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 002823f0 00 00 00 00 00 00 00 00 00 00 00 00 03 fa 00 0e |................| 00282400 00 00 00 00 00 00 00 00 02 00 00 01 00 00 00 00 |................| 00282410 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 002827f0 00 00 00 00 00 00 00 00 00 00 00 00 03 fa 00 0e |................|
-Mark
Mark,
MD> On Apr 29, 2004, at 7:25 AM, Pierre Duhem wrote:
I didn't like very much the code I had to check for an overflow of the binary table used in the Extents and Catalog B-trees for the node allocation.
Therefore, I had the idea to build this list when formatting. I followed the specs and built a simply linked list from the tree header. All nodes are empty, with only the downward pointer, the 2 as node kind, a 1 since there is a single entry and the two offsets at the end, 00 0E for the binary table and 01 FC (in the case of a HFS node) pointing to itself.
But Mac OS X doesn't seem to like my idea, refuses to mount even an empty volume, as soon as there is a map node linked list.
Who should build this list? Is it against the rule to build an empty node list?
MD> The B-trees keep track of which nodes are used and which are free by MD> using one or more map records. These map records are just a bitmap, MD> much like the one that is used to keep track of used/free allocation MD> blocks. The first map record is in the B-tree header node (node #0). MD> If the B-tree contains more nodes than there are bits in the header MD> node's map record, then there will be additional map nodes which each MD> contain a single map record. The header node and map nodes form a MD> singly linked list, using the forward link field (the first four bytes MD> of the node). If your B-tree is large enough (has enough nodes), then MD> you definitely do need to create the linked list of map nodes at format MD> time.
OK. This is also what I thought. It is definitively simpler to do it a formatting time.
MD> Similarly, you may have to add map nodes to the end of the MD> linked list if you grow the B-tree (if it now has more nodes than the MD> existing map nodes can track).
MD> It should be OK to create more map nodes than your B-tree strictly MD> needs. I don't think Mac OS X will complain, but third party repair MD> utilities might. Note that Mac OS X will only grow, never shrink, a MD> B-tree.
MD> Some things to verify: MD> * The linked list uses the forward link field in the node header. This MD> is the first four bytes of the node. It should contain the node number MD> of the next node in the linked list, stored in big endian (network) MD> byte order. The forward link of the last node in the linked list MD> should be zero. MD> * The backward link (bytes 4-7 of the node) should be zero. MD> * The node type (byte 8) is 1 for the header node, or 2 for the map MD> nodes. MD> * The node height (byte 9) should be zero for both the header node and MD> map nodes. MD> * The number of records (bytes 10-11) of the map nodes should be set to MD> 1 (again, in big endian, so 00 01). MD> * Bytes 12-13 of the nodes should be zeroes. MD> * The offsets at the end of the node are in the opposite order of the MD> keys in the node. For example, the offsets for HFS (node size = 512) MD> would be the bytes 01 FC 00 0E. The offset (0x000E) for the first MD> record is at the end of the node; the offset for the next record MD> (0x01FC, free space) comes just before that; and so on. MD> * On HFS Plus, the size of a map record must be a multiple of 4 bytes. MD> Since the node header is 14 bytes (not a multiple of 4), and there are MD> two record offsets (4 bytes), there will be two free bytes between the MD> map record and record offsets in a map node. That is, the second MD> offset (the offset to free space) will be the node size minus 6 (bytes MD> xx FA).
Thanks for pointing me at this. My code was wrong. I'll correct it.
MD> * Don't forget to mark the header node and any map nodes as in use in MD> the map record(s).
I already did it.
MD> If that doesn't help you figure out the problem, let me know.
MD> By the way, if you want to experiment with how Mac OS X formats MD> volumes, try using disk images. You can use sparse disk images to MD> create volumes much larger than you have physical space for. For MD> example, here's how I created a sparse image of an 80GB HFS Plus MD> volume, with an extents B-tree containing 10,000 nodes, with a node MD> size of 1024:
Thanks. Bus, as I said in another message, I do all this on a PC under Windows.
When the system tries to mount my disk (40GB, formatted as HFS), it aborts with an error, and the Disk utility, when asked to check the disk, displays (retranslated from the French): Testing Extents Overflow File Invalid Map Node link. This disk must be repaired (but the Repare button remains greyed).
Norton Disk Doctor (v. 8) hangs somewhere, without any message.
On the other hand, since it was childish to try to format such big disks in plain HFS (I now automatically switch to HFS+ from 4GB), the problem will disappear, but I'm not quite satisfied.
-
 Mark Day
Mark Day -
 nand@gmx.de
nand@gmx.de -
 Patrick Dirks
Patrick Dirks -
 Pierre Duhem
Pierre Duhem -
 Pierre Duhem
Pierre Duhem -
 Rob Leslie
Rob Leslie -
 Simon Bazley
Simon Bazley